Section 1 - STL Sets and Pairs
9B.1.1 Return to STL
For the past nine and a half weeks we have rolled up our sleeves and designed out of whole cloth, a number of ADTs: vectors, lists, hash tables, a number of different tree types, heaps, and some of the algorithms that they support. Today, however, we are are going to take a vacation from ADT design and review, or in some cases introduce, the STL versions of many of the data structures we've studied. We do this for several reasons.
First, this is a class in C++ data structures. Besides learning to implement an ADT using C++ I can't let you out into the world without knowing how to use STL sets, maps, queues, etc. Employers will expect it, and you will need to be able to read other programmers' posts when they use these things.
Second, once you are comfortable with the STL containers, you can make an educated determination about whether you want to use an ADT you have built or use the STL version You even have some profiling tools (our timers) to help benchmark some differences.
Finally, and this is very important for you in these final two weeks, we are going to study Graph Theory. In doing so, I have decided to build all of our graphs on STL containers, rather than the "FHcontainers" we have written. This will give you some additional practice with STL, and you will see that graph design is often done just to get some answers and not meant for massively scaled data access. This takes the performance pressure off the algorithms and allows us to implement them in ways that might not be optimized for speed. Don't get the wrong idea. I'm not saying that all graph applications can be written using slow or inefficient underlying data structures. However, it is more common to find a non-time critical graph application than it is a binary search tree or hash table.
9B.1.2 Sets
We start with the set. If you studied sets in math, you may already know that sets are "collections of objects", whatever that means. STL sets have some properties that are common to most ADT set implementations:
- Sets cannot contain duplicate items
- The underlying data that you place into sets must have an ordering relation, typically using the default < operator.
The idea that sets cannot contain duplicates is sometimes misunderstood. For primitive types like ints, it presents no problem. If there is a 4 already present in a set, and you attempt to insert a 4, the insertion will not do anything:
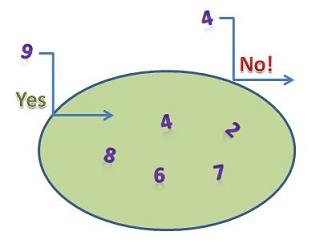
Since there is no 9, yet, the insertion of the 9 would go through without a hitch. Typically, a client would call some_set.insert(val); and the insertion would either succeed or fail, but the client might not care which (and would then not need to test the return value). The client is just building a collection, and if val is already in the collection, so be it. You will see many examples of this because advanced programmers use sets constantly and so shall we in the next couple weeks.
If the underlying data type is not primitive, then we usually define the < operator ourselves to meet our particular needs. For example, maybe we have an Employee class with a name and num field. If we define operator<() using the name field, we will get an alphabetical ordering, and if we define it using the num field, we will get a numerical ordering. The important concept for you to understand here is that the property of "already being in the set" is relative to which field the data uses as its < operator.
Let's say we defined < like this:
bool operator<(const Employee &rhs) const
{
return (name < rhs.name);
}
This, then, is how the set will determine whether two Employees are the same. Whichever field is used for the < operator is said to be the "order field" or "key field".
So, we would get the following behavior if we attempted to insert these two elements into the set:
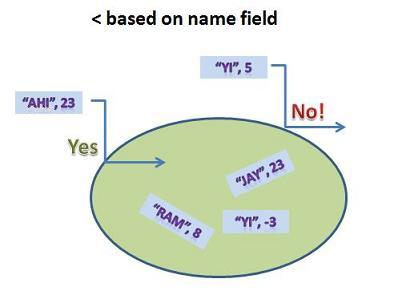
The set doesn't allow "YI" to be inserted since there already is a "YI" in the collection, but it is fine with "AHI", even though there is a member ("JAY") who has num = 23.
Now, we try it the other way. What happens if we define the < operator using the num values:
bool operator<(const Employee &rhs) const
{
return (num < rhs.num);
}
We get a different result:
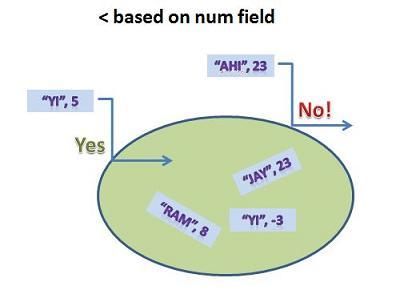
"YI" is allowed in because the order field is no longer name. There is no object with a 5 in its num field, and that's all the set cares about. So, when you are working with sets, remember to think about how < is defined. By the way, the == operator has nothing to do with it. Most container classes, including those that we wrote, only use the < operator. The == operator does not even have to be defined. I'll leave it as a question you can answer on your own, or in the forums, as to how an ADT uses < (and only <) to determine whether two objects are equal.
9B.1.3 Examples of STL Set Coding
First we start with a simple class that demonstrates the concept we just learned.
// A Set Of Objects
// CS 2C Foothill College
#include <iostream>
#include <string>
#include <set>
using namespace std;
class Employee
{
public:
static int sortKey;
string name;
int ss;
Employee(string n, int s) : name(n), ss(s) {}
void show() const { cout << name << " " << ss << endl; }
bool operator<(const Employee &rhs) const
{
return (name < rhs.name);
}
};
int main()
{
Employee e1("mike", 35), e2("harvey", 5), e3("don", 2);
set<Employee> company;
set<Employee>::iterator iter;
cout << "---------- The 'loose' objects ------ " << endl;
e1.show(); e2.show(); e3.show();
// insert them into the set
company.insert(e1); company.insert(e2); company.insert(e3);
cout << "---------- The contents of the Set ------ " << endl;
for ( iter = company.begin(); iter != company.end(); iter++)
iter->show();
// change mike's ss# and try to insert again
e1.ss = 99;
company.insert(e1);
cout << "----- After trying to insert e1 again ------ " << endl;
for ( iter = company.begin(); iter != company.end(); iter++)
iter->show();
}
As you would expect, once the set is populated with some elements, it won't take any duplicates. And because of how our < operator is defined, a new Employee with the name "mike", will be a duplicate:
---------- The 'loose' objects ------ mike 35 harvey 5 don 2 ---------- The contents of the Set ------ don 2 harvey 5 mike 35 ----- After trying to insert e1 again ------ don 2 harvey 5 mike 35 Press any key to continue . . .
But, change the < operator to compare using ss#:
bool operator<(const Employee &rhs) const
{
return (ss < rhs.ss);
}
And this time, mike gets into the party:
---------- The 'loose' objects ------ mike 35 harvey 5 don 2 ---------- The contents of the Set ------ don 2 harvey 5 mike 35 ----- After trying to insert e1 again ------ don 2 harvey 5 mike 35 mike 99 Press any key to continue . . .
9B.1.4 Other Set Methods
The set container has a lot of the expected functions. Here are a few:
- empty()
- clear()
- begin() and end()
These do exactly what they do in all STL classes (and in our FH classes).
Also, you have access to all the standard operators like = (assignment) and == (equality).
The operators that requires some analysis and discussion are:
- find()
- insert()
- erase()
And we do that now.
STL's set has no pop() or top() method that returns an item. There is an erase(), but it requires an iterator that is pointing to the object you want "erased". Sets are not meant to store data the way a queue or stack is - if you want to get something from a set, you can't say "give me the next item, please". Rather you have to know what you 're looking for. If you want to remove ("mike", 35) from the set, you have to first construct an object with "mike" (or 35, depending on the order key field) as a member and then do a find on that object. If you found something, an iterator pointing to it will be returned, and you can pass that iterator back into erase() to get rid of it:
To show that find() really doesn't care about any fields other than order-key, I will change e1's ss# before using it to find "mike", and we observe that it still finds it:
// change e1's ss# -- because the data is name-orded we can still
// use e1 to find "mike"
e1.ss = 99;
iter = company.find(e1);
if (iter != company.end())
{
cout << "found mike, and I will delete him now" << endl;
company.erase(iter);
}
else
cout << "mike not found" << endl;
cout << "----- Here is the set now ------ " << endl;
for ( iter = company.begin(); iter != company.end(); iter++)
iter->show();