Section 4 - Completing the FHlist Class
2B.4.1 The Iterator-Returning Methods: begin() and end()
Now that we have iterators, we can blast through the remaining FHlist method definitions. We are back inside the FHlist class template. Sometimes we will be defining methods inline and at other times, we'll define them externally (to the prototype). The same syntax we have seen will indicate which is which. Notably, if we see the scoping operator, ::, we know we are outside the class prototype, and if not, we know we are in-line. Any method defined outside the class requires its prototype within the class prototype which you should, by now, be able to produce in your sleep once you see the definition.
The fundamental methods that require iterators are the ones that generate them for the client, namely, begin() and end(). Don't be confused: begin() and end() are FHlist methods, not iterator methods, but they do return iterator objects. Recall from our bullet point of goals:
- FHlist's begin() will return an iterator that points to the first real Node (which means that, internally, it points to the same node mHead->next points).
- FHlist's end() will return an iterator that points one item beyond the last real Node (which means it points directly at the same Node at which tail points.)
With that intro, we show these definitions: a pair each for the const and non-const FHlist methods (in-line, obviously):
const_iterator begin() const { return const_iterator(mHead->next); }
const_iterator end() const { return const_iterator(mTail); }
iterator begin() { return iterator(mHead->next); }
iterator end() { return iterator(mTail); }
2B.4.2 The Assignment Operator and Copy Constructor
We can finally reveal the definitions for these two methods (which were omitted earlier because they use iterators). The assignment operator will provide a deep copy, so necessary with a data structure like a list, where the object itself consists only of a couple miniscule pointers, while the bulk of the data is floating outside the object, but controlled by it -- i.e., "deep". The method operator=() should be self explanatory. So have your "self" look at it and do the explaining:
template <class Object>
const FHlist<Object> & FHlist<Object>::operator=( const FHlist & rhs )
{
const_iterator iter;
if ( &rhs == this)
return *this;
clear();
for (iter = rhs.begin(); iter != rhs.end(); ++iter)
this->push_back( *iter );
return *this;
}
The copy constructor always falls into place once the assignment operator is done:
FHlist( const FHlist &rhs ) { init(); *this = rhs; }
2B.4.3 insert() and erase()
Next we add functionality that allows us to insert a Object into the middle of the list. We were able to design push_back() and push_front() to provide this functionality on the extremes of the list, but we had no way of specifying an internal location as a place to put the Object. Now that we have iterators, we can give a client a way to insert an Object anywhere in the list that an iterator (also supplied by the client) points. In other words, our insert() method will take both an Object to insert and an iterator before which we will insert the new Object . A new Node will be manufactured to hold the object, then the node will be inserted into the list directly before the iterator. (In my earlier classes, I discussed an insertAfter() method. The method we are about to write acts more like an insertBefore().)
Here is insert(). You might notice that I am defining it in-line in order to avoid dealing with syntaxual difficulties that would arise had we defined them outside the class:
// syntax too difficult to define outside
iterator insert( iterator iter, const Object &x )
{
Node *p = iter.mCurrent;
if (p == NULL)
throw NullIteratorException();
if (p->prev == NULL)
throw NullIteratorException();
// build a node around x and link it up
Node *newNode = new Node(x, p->prev, p);
p->prev->next = newNode;
p->prev = newNode;
iterator newIter(newNode, *this);
mSize++;
return newIter;
}
As we have done in the past, we throw an exception if the iterator is pointing to a NULL or to an Object that does not have the requisite predecessor (or, in other situations, successor). You can draw pictures to convince yourself that the new Object, x, is being correctly linked-in to the list prior to iter:
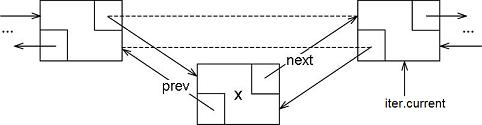
Next, we provide erase() which removes the Object referenced by the iterator iter. We must clean-up by deleting the Node that holds the Object. If you are worried about the actual Object data within Node, don't. We did not instantiate that, so we are not responsible for deleting it. We mustn't even try. Looking at this same concern differently, the deletion of the Node *p does not harm the Object wrapped inside.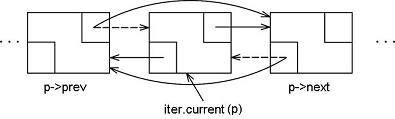
iterator erase( iterator iter )
{
Node *p = iter.mCurrent;
if (p == NULL)
throw iterator::NullIteratorException();
if (p->prev == NULL || p->next == NULL)
throw iterator::NullIteratorException();
iterator retVal(p->next, *this);
p->prev->next = p->next;
p->next->prev = p->prev;
delete p;
mSize--;
return retVal;
}
A common overload of erase() is one that takes two iterators, start and stop, and removes everything from start up to, but not including, stop. This start-stop, protocol is very common in STL algorithms, as we'll see when we get to sorting:
iterator erase( iterator start, iterator stop )
{
if (start.mCurrent == NULL || stop.mCurrent == NULL)
throw NullIteratorException();
if (start.mCurrent->prev == NULL || start.mCurrent->next == NULL
|| stop.mCurrent->prev == NULL)
throw NullIteratorException();
for (iterator iter = start; iter != stop; )
iter = erase(iter); // if this throws, then mCurrent erase() will throw, too
return stop;
}
2B.4.4 Final Precautions
I will add one additional layer of safety to the above code, and then we can move on to play with all our new toys.
We were cautious about our mutators above. We tested the iterators to be sure that they not only pointed to real Nodes, but that those Nodes were well within the boundaries of some list, meaning we could tinker with the links of the predecessor and successor, without hitting our head against a NULL. Are we safe? Not quite. Check this out. Let's delete the "middle" of a possibly big list. That is, let's start a couple Nodes into the list and erase everything up to a couple Nodes before the end of the list. This is easy enough to do (no error yet):
FHlist<int>::iterator start = ++(++fhList.begin()); FHlist<int>::iterator stop = --(--fhList.end()); fhList.erase( start, stop );
If we place this code fragment in an appropriately designed main(), which has a built-up fhList with some Nodes, it would erase the middle of the list as advertized, leaving only four Nodes. It's kind of fun to see how nicely the ++ and -- operators work to stroll forward and backward in the list.
But what about this?:
FHlist<int>::iterator start = ++(++fhList.begin()); FHlist<int>::iterator stop = --(--fhList2.end()); fhList.erase( start, stop );
Do you notice anything funny? Here's an even simpler version of the same error:
FHlist<int>::iterator stop = --(--fhList2.end()); fhList.erase( start, stop );
If you still don't see the error, I advise you to spend a couple days on the comics page of your local newspaper, where you'll find the puzzle that asks you to find at least X differences between the two pictures. We are passing an iterator from one list to the erase() method of a different list. Normally, the program will crash, (although there are ways the program might not crash, but the list will be mutilated). Either way, we can and should guard against this since it is so easy to do. It requires, however, a small modification to our iterator class. We need iterators to know which lists they are currently working on. How is this done? Carefully:
- We add a member FHlist * mMyList to the iterator class. This will point to whichever list the current iterator belongs to (and that might change, as the program progresses, which is fine.)
- We assign mMyList a value within the methods FHlist::begin() and FHlist::end(), which are often where iterators are born. This will start any iterators out, knowing to what list they belong. The ++ operator won't change this member so as long as there is no new assignment, we'll be fine.
The details are a little ugly. You are not responsible for them, but they are all incorporated into FHlist.h. Here are the highlights. First, you have to change the protected constructor in const_iterator to take a second parameter, the list that is its initial owner (owners can change later):
// protected constructor for use only by derived iterator and friends
const_iterator(Node *p, const FHlist<Object> &lst) : mCurrent(p), mMyList(&lst) { }
Then, you find places where that constructor was invoked, namely, within the definitions of begin() and end(), and fix those to be compatible with the new signature. For example:
const_iterator begin() const { return const_iterator(mHead->next, *this); }
As you can see, we are passing the *this object to the iterator constructor, letting it know who daddy is. Next, you add a new exception to the FHlist class:
class IteratorMismatchException { };
and finally, you throw the exception when you detect trouble, in the erase() and insert() methods, notably. For example:
iterator erase( iterator start, iterator stop )
{
if (start.mMyList != this || stop.mMyList != this)
throw IteratorMismatchException();
// etc ...
In our client, we can test:
FHlist<int>::iterator start = ++(++fhList.begin());
FHlist<int>::iterator stop = --(--fhList2.end());
try
{
fhList.erase( start, stop );
}
catch (FHlist<int>::NullIteratorException)
{
cout << "Iterator Null Pointer!\n";
}
catch (FHlist<int>::IteratorMismatchException)
{
cout << "Iterator Mismatch!\n";
}
I will remind you that you are not responsible for these details. However, if you are a real C++ type, you might as well get comfortable with this level of detail by studying FHlist.h and seeing how it all goes together. You will be using FHlist, even if you don't make changes or improvements to it (which I hope you will will try to do!), so knowing this last block - how to detect errors in your client -- is something I expect you to know.
Are there still weaknesses in this class? Sure. However, we have as much or more protection than is afforded by STL lists, and a good client can take precautions for anything we left out.
We did it. A reasonably complete FHlist class which is compatible with STL list as far as we have taken things. We are done with the implementation. We can now use FHvector and FHlist to create the many data structures of CS 2C.