Section 2 - Phase 1 Implementation Without Iterators
As we did with FHvector, we are going to create a class template, FHlist, that will mimic, but have superior performance to, the STL list class. It will contain all of the methods and iterators associated with a grown-up list.
We tread carefully, however. A typical implementation of a list container would include a nested iterator class which is integral to the definition of almost all methods, even the most basic ones like the destructor and push_XYZ(). Such an implementation requires defining the iterator before proceeding with all other methods. FHlist will not follow that approach for two reasons:
- Since many of the simpler list functions can be done without iterators, we can get a basic list template working from first principles, minus the iterator class, thus providing us a shortest path to a partially complete, but fully functional, intermediate stage list template. This simplifies our logic, makes it easy to discuss the method definitions, and gets us to a working program on which we can build the later methods, including the iterator class.
- Incorporating the iterator into the elementary methods, while looking short and sleek, has an associated performance cost. By defining these more elementary methods without using iterators, our FHlist class will have better performance results. This is useful since some clients will use these elementary methods (e.g., a stack client that only needs the push/pop functionality), and we give those clients the fastest possible execution time.
Clarity of source code and speed in execution -- these are two desirable properties to recommend our approach. We will be able to implement constructors, destructors and push/pop methods without iterators. These will behave exactly like the STL list class with the minor exception that our push/pop methods will never crash an unvigilant client, while the STL list class (and the implementation in the text) will bring the same client to its knees for no really good reason. To wit, if a client tries to pop() off of an empty list, there is no reason why the list class can't silently return, or at least throw an exception. While we will not throw an exception (in order to be compatible with STL lists) we will certainly not force a program crash as that template does.
In what follows, we will keep in mind that an empty list consists of a header and tail node, meaning that all real data nodes will be inserted (and removed) between these. Header nodes (and tail nodesin doubly linked lists, such as we are using here) should be considered required in any list implementation since they simplify the logic of most methods.
2B.2.2 An Nested Node Class
We will create a doubly-linked list. But a list of what?
All lists are built from nodes. A node must contain the linking information (next and prev pointers) and the payload data. It is customary, although not required, to define the node class within the list class. This hides the identifier "Node" from clients, avoiding name conflicts. However, one could just as easily create a sibling, rather than a nested, node class. Keep this in mind as you follow along. A Node object is really a separate object that can be considered to live outside the actual list object, even when its class definition happens to lie within the list class prototype.
If this idea is hard for you to grasp, look at the actual private data within the list class (presented momentarily). It consists of Node pointers, not Node objects. The Nodes themselves are not properly part of the list object, although they are certainly managed by, and are the responsibility of, the list object.
This reminds us of a fundamental OOP concept: the definition of a type (i.e., a class) has no instantiation power. It is only a blueprint. No objects are created.
Here is the actual definition of the Node type which is prototyped inside the FHlist class (at the top) and defined after; because of the prototype and this special definition notation, it is considered to be nested inside the FHlist class, and available only to that class.
First the prototype, declaring that class Node is nested in class FHlist:
template <class Object>
class FHlist
{
... etc. ...
// Node prototype - this nested template is defined outside
class Node;
... etc. ...
};And near the end of the same file, the definition, with syntax that links it to the FHlist class:
// definition of nested FHlist<Object>::Node class ----------------------
template <class Object>
class FHlist<Object>::Node
{
public:
Node *prev, *next;
Object data;
Node( const Object & d = Object(), Node *prv = NULL, Node *nxt = NULL )
: prev(prv), next(nxt), data(d)
{ }
};
With this constructor, we can instantiate a new Node with its prev and next pointers already pointing to the correct Nodes in the list. This means that after the Node is created, its data is all set -- we will only have to adjust the pointers in the neighboring nodes to complete the linkage of this new node into the list.
Typically, we create a Node in some insert or push() operation in which we are handed an Object. The drill will be to wrap that Object into a new Node, which is easily done simply by passing that Object to the Node constructor. Here is a preview of how the constructor typically gets called in a push() operation, defined in the FHlist class:
push_front( const Object &x )
{
Node *p = new Node(x, mHead, mHead->next);
// etc. ...
The point is this: we manufacture the new Node with all the information it needs to be incorporated into its proper place in the list. We tell it what Object it will contain and where it will point.
Reminder: k_and_r Notation
We continue to name methods consistently with the STL conventions using k_and_r() names, rather than camelCase() names. Similarly, we'll prefix member variables using m_. Otherwise, we will lean toward camelCase for most private and local variables.2B.2.3 Private Data of FHlist
An FHlist object really only needs three things, two Node pointers and a size. The list will grow outside of the FHlist object through its constituent Nodes' next and prev links. Here is the data:
template <class Object>
class FHlist
{
private:
// private data for FHlist
int mSize;
Node *mHead;
Node *mTail;
// etc. ...
}
Our basic FHlist methods mostly involve "putting-on" or "taking-off" things at the front (mHead) or the tail (mTail) of the list.
2B.2.4 FHlist Default Constructor
Our default constructor will build an empty list consisting of two bookkeeping nodes, the header node and the tail node. We let a private init() method do the work, since we will use this elsewhere and do not wish to repeat the logic.
FHlist() { init(); }
This was defined in-line as you can see by the omission of the scoping operator, ::, and single-line syntax (something I only do with short in-line functions like accessors). Here is init(), which gives birth to the header/tail nodes. As a reminder, here is the picture of an empty list:
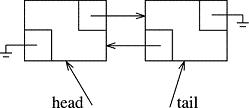
template <class Object>
void FHlist<Object>::init()
{
mSize = 0;
mHead = new Node;
mTail = new Node;
mHead->next = mTail;
mTail->prev = mHead;
}
Use a pencil and paper to see how this links up the two nodes. Make sure you understand the difference between mHead, a tiny pointer that refers to a Node and the header Node itself. Same with mTail.
Also, take a moment to take-in the possible disaster that this kind of method might precipitate. If it were to be called willy-nilly by some well-meaning client, we would have memory leakage. A large list would not only be lost, but all the memory would be locked and dead. Even an empty list causes the two bookkeeping nodes to go into limbo. Therefore, we make this method private, and we must be careful that we only call it from constructors, never mid-life of an object. This is a good place to look up and really understand what I am saying. It's better to get clarity on these elementary, but necessary, issues now, before things get complicated in a few weeks when we'll be concerned with more important things.
We will defer the definition of the copy constructor until we introduce the list iterator, as there is no easy non-iterator implementation of a copy constructor.
2B.2.5 Pops and Pushes
Next come the pops and pushes. We can do this from either the front or back of the list. The definitions involve very little, but we do have to be careful -- every detail matters, and any unnecessary maneuver costs precious resources. Study these, also using a pencil and paper to diagram them. The prototypes are omitted - you can construct them from the definitions. Also, I'm only showing you the push/pop front methods. The tail versions are identical with head replaced by tail, next replaced by prev, etc. You can see them in the header file FHlist.h.
template <class Object>
void FHlist<Object>::pop_front()
{
Node *p;
// safer, but a little slower with this test
if ( mSize == 0 )
return;
p = mHead->next;
mHead->next = p->next;
mHead->next->prev = mHead;
delete p;
mSize--;
}
template <class Object>
void FHlist<Object>::push_front( const Object &x )
{
Node *p = new Node(x, mHead, mHead->next);
mHead->next->prev = p;
mHead->next = p;
mSize++;
}
In push_front(), we package the object in a newly instantiated Node, then adjust the existing pointers inside both the header node which mHead points to and the first data Node (which will be dethroned by our new Node containing x). In pop_front() we must unlink the first data Node and delete it. The if statement in pop() allows the client to call us with an empty list and not get an ugly crash. The overhead is minimal. Furthermore, by not using iterators, we make up the overhead, and then some. An alternative implementation might throw an exception rather than returning silently.
2B.2.6 The Destructor and clear()
I presented the pushes and pops first, before the destructor, because we need pop_front() in order to retire an object. Now that we have that method we can present the destructor.
When cleaning out our list we need to remove and destruct every Node in the list. Here is the destructor and its helper, the publically callable clear(). First, the in-line destructor (ugly, because it's all on one line, but we'll take it, today):
~FHlist() { clear(); delete mHead; delete mTail; }
And now, clear():
// public interface
template <class Object>
void FHlist<Object>::clear()
{
while ( mSize > 0 )
pop_front();
}
2B.2.7 size() and empty()
Next, we do a couple easy ones, in-line:
bool empty() const { return (mSize == 0); }
int size() const { return mSize; }
Not much to say about these.
2B.2.8 front() and back()
We already have a complete template which we can test by pushing and popping items and testing the size. However, we cannot actually see what we are popping, so we complete the picture with front() and back() which return objects that can then be sent to the screen for observation. This will complete phase 1, the iterator-free subset of the FHlist class template.
Because these are short, we implement them in-line. Also, since there is a header and tail node, we don't require any testing - the client cannot crash the program by calling them. The overloading of const versions allows us to use const or normal references with these accessors.
Object & front() { return mHead->next->data; }
const Object & front() const { return mHead->next->data; }
Object & back() { return mTail->prev->data; }
const Object & back() const { return mTail->prev->data; }
2B.2.9 A Test Client and Sample Run
Okay, we're ready. Fasten your seat belts. We'll push some ints onto the front and back of the list and then pop them off each end, displaying as we do. This demonstrates a fully functional but partial list template.
// Test and demo of FHlist class template
// CS 2C, Foothill College, Michael Loceff, creator
#include <iostream>
#include <string>
using namespace std;
#include "FHlist.h"
// --------------- main ---------------
int main()
{
int k;
FHlist<int> fhList;
fhList.push_back(1);
fhList.push_back(2);
fhList.push_back(3);
fhList.push_back(4);
fhList.push_back(5);
fhList.push_back(6);
fhList.push_front(0);
fhList.push_front(-1);
fhList.push_front(-2);
fhList.push_front(-3);
cout << fhList.size() << endl;
for (k = 0; k < 4; k++)
{
cout << fhList.front() << " " << fhList.back() << endl;
fhList.pop_front();
}
cout << endl << fhList.size() << endl;
for (k = 0; k < 12; k++)
{
cout << fhList.front() << " " << fhList.back() << endl;
fhList.pop_back();
}
cout << endl << fhList.size() << endl;
return 0;
}
/* -------------------------- RUN --------------------------
10
-3 6
-2 6
-1 6
0 6
6
1 6
1 5
1 4
1 3
1 2
1 1
0 0
0 0
0 0
0 0
0 0
0 0
0
Press any key to continue . . .
-------------------------- END RUN -------------------------- */
2B.2.10 Benchmarks
This page is long, but it's mostly simple code, so I'll indulge in a little benchmarking, even with this partially completed template. Surely, there can't be that big a difference between our push_front() and that of the STL version. Of course, if that were true, I wouldn't be having fun adding this, the 10th section of the current page. Let's see the difference.
// Benchmark for FHlist vs. STL list
// CS 2C, Foothill College, Michael Loceff, creator
#include <iostream>
#include <string>
using namespace std;
#include "FHlist.h"
#include <list>
// for timing our algorithms
#include <time.h>
clock_t startClock();
double computeElapsedTime(clock_t startTime);
void displaySeconds(string message, double time_in_secs);
// --------------- main ---------------
#define SIZE 200000
int main()
{
int k;
clock_t startTime;
double elapsedTime;
startTime = startClock(); // START TIME START TIME START TIME ----------
FHlist<int> fhList;
for (k = 0; k < SIZE; k++)
{
fhList.push_front(-k);
fhList.push_back(k);
}
for (k = 0; k < SIZE; k++)
{
fhList.front(); fhList.back();
fhList.pop_front();
fhList.pop_back();
}
elapsedTime = computeElapsedTime(startTime); // STOP TIME STOP TIME STOP TIME -----
displaySeconds("Time for FH list: ", elapsedTime);
startTime = startClock(); // START TIME START TIME START TIME ----------
list<int> stlList;
for (k = 0; k < SIZE; k++)
{
stlList.push_front(-k);
stlList.push_back(k);
}
for (k = 0; k < SIZE; k++)
{
stlList.front(); stlList.back();
stlList.pop_front();
stlList.pop_back();
}
elapsedTime = computeElapsedTime(startTime); // STOP TIME STOP TIME STOP TIME -----
displaySeconds("Time for STL list: ", elapsedTime);
return 0;
}
// for timing our algorithms
clock_t startClock()
{
return clock();
}
double computeElapsedTime(clock_t startTime)
{
clock_t stopTime = clock();
return (double)(stopTime - startTime)/(double)CLOCKS_PER_SEC;
}
void displaySeconds(string message, double time_in_secs)
{
cout << "Elapsed time for " << message
<< time_in_secs << " seconds." << endl;
}
/* -------------------------- RUN --------------------------
Elapsed time for Time for FH list: 0.109 seconds.
Elapsed time for Time for STL list: 0.266 seconds.
Press any key to continue . . .
-------------------------- END RUN -------------------------- */
The difference is .109 seconds vs. .266 seconds, with optimization turned on. FHlist is over twice as fast as STL's list. If optimization is turned off, then the difference is even greater. Not bad for a few hours work, and we can use this template for the rest of our lives. Let's now invest a few more hours ( I'm the one investing the hours -- you only have to experiment with it, which should take you less than an hour) and get the rest of this class written. Good work.
The results on Mac/Linux are similar (see below). FHlists still beat STL lists.
Elapsed time for Time for FH list: 0.071932 seconds. Elapsed time for Time for STL list: 0.108951 seconds
Try this on your compiler and let us know how your figures vary.