Section 2 - The First Real C++ Data Structure Project
2A.2.1 Follow This Construction
 To be sure there is no misunderstanding, for this construction and those that follow, you should digest every line of code that I present, along with the commentary. At times, I will craft code and commentary a little differently from what is in the text. This is specifically for you, my Foothill College CS 2C students. So take advantage of that fact. Allow yourself time to really take-in the step-by-step development of each method prototype and definition, and ask in the forums if you don't understand something.
To be sure there is no misunderstanding, for this construction and those that follow, you should digest every line of code that I present, along with the commentary. At times, I will craft code and commentary a little differently from what is in the text. This is specifically for you, my Foothill College CS 2C students. So take advantage of that fact. Allow yourself time to really take-in the step-by-step development of each method prototype and definition, and ask in the forums if you don't understand something.
The FH class templates in this course, including this first class FHvector.h, are part of your course download. They can be retrieved in .zip format using the method in the Downloading Header Files Module. You can copy FHvector.h into your project folder and include it in your project. That way, not only can you use the classes, but you can click-on and open the files to see any code that I omit in these modules. (Due to updates and corrections the code in the modules may differ from time-to-time from what is in the .h file.)
So, get FHvector.h now and put it into your project folder. Then open your IDE and make sure that FHvector.h is also added to the project as an include file, so you can quickly access it from your experimental clients. When that is in place, and you have set aside some alone time, you are ready to enjoy the module, which begins now.
2A.2.2 An Alternative to STL vector: FHvector
We've already noted how the STL vector is
- more flexible than an array, offering some bounds protection, yet
- often much slower than an array.
Our mission is to devise our own template class FHvector from first principles that is just as good a STL vectors but faster. We will call this template FHvector. We are going to parallel many of the STL vector names and methods so that using FHvector is almost the same as using STL vector. You will be provided with a header file FHvector.h that contains a complete implementation of FHvector and you can use it and change it without restriction.
k_and_r Naming Convention
Because we are attempting to build class templates which are interchangeable with those in the STL, we will parallel the method names (and often variable names) even though this means using k_and_r rather than camelCase naming conventions for most public and some private names. Hence, we will use push_back() rather than pushBack(), etc.We will start with a goal in mind, and build toward that goal. Here are some desirable attributes we would like to see in a vector-like container FHvector:
- A flexible size that starts at 0 (or some finite amount) specified in a constructor, but changes as needed. size represents how many objects are actually stored in the container at any given time.
- A separate number, the capacity, which is larger than the size and represents how many elements we can add to the container without doing any back-breaking memory acrobatics. (The capacity will represent how big the internal array, in its current state, really is, while size represents how many array locations we are using.)
- The ability to increase the capacity or size manually, through reserve() or resize(), respectively, or have them grow automatically as we add elements to the container through push_back().
- A bracket operator member function that is both used as a mutator and accessor.
- An assignment operator that copies one FHvector to another.
- Bounds checking with the bracket operator, and error reporting through exceptions. This will obviate the need for at() since our brackets operator will do bounds checking, always.
- Methods back(), front(), push_back(), pop_back(), empty(), size(), capacity(), clear(), erase(), resize() and reserve(), that mimic the corresponding methods in the STL vector template.
- An iterator for this class that behaves like STL vector iterators, with begin(), and end().
Writing this class will teach us more about the STL vector class and will also give us some good experience with template building. While I am going to provide you with the definitions, you might think of ways to implement the methods that you feel are better. I encourage you to try them and see.
The private data is very simple (we will use the prefix m to emphasize that the variable is an instance member):
private: int mSize; int mCapacity; Object *mObjects; static const int m_SPARE_CAPACITY = 16;
You can already see what's going to happen. We will be allocating a dynamic array and accessing it using mObjects. As needed, we will re-allocate and copy the old values into the new array.
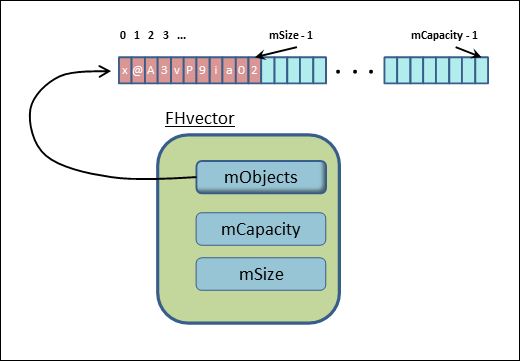
When we do need to expand the internal array, we will always make sure that capacity is larger than size by at least 16 objects worth, which we of course symbolize as SPARE_CAPACITY.
I use the prefix m_ to indicate a member of our class template. This is one convention used in industry. I will not stick with this in the course, but will expose you to various styles.
We will be implementing the template using the two-stage prototype/definition format. The prototype will look like this:
template <class Object>
class FHvector
{
private:
int mSize;
int mCapacity;
Object *mObjects;
static const int m_SPARE_CAPACITY = 16;
public:
FHvector( int initSize = 0 );
void pop_back();
... etc
private:
void setSize(int size);
... etc.
}
and a typical definition will look like this:
template <class Object>
void FHvector<Object>::pop_back()
{
if (mSize > 0)
mSize--;
}
As usual, we will prototype all classes, including templates, and keep their definitions separate and below the prototype so as to make the interface of the container easy to read and use. We will, however, put both parts into the .h file, as is customary with templates (in contrast to ordinary classes which we separate into .h and .cpp files).
2A.2.3 The Constructors, operator= and Destructor
The basic constructor allows an optional size parameter. It will generate size + m_SPARE_CAPACITY elements in the array. I am using two private mutators (an oxymoron, but that's actually what they are) so as to prevent a bad value coming in from the client to the constructor. We'll start with them. They are quite easy:
// private utilities for member methods
template <class Object>
void FHvector<Object>::setSize(int size)
{
mSize = (size < 0)? 0 : size;
}
template <class Object>
void FHvector<Object>::setCapacity(int capacity)
{
mCapacity = ( capacity <= (mSize + m_SPARE_CAPACITY) )?
mSize + m_SPARE_CAPACITY : capacity;
}
I will not show the prototypes, since you can reconstruct them from the definitions. The first simply guards against a negative size, and the second assures that the capacity will always be set to at least mSize + m_SPARE_CAPACITY. (We don't have to worry about mSize > mCapacity in setSize() because we will always call setSize() before setCapacity() in our container methods. These are not true mutators, but convenience functions.)
The simple constructor merely sets the initial size and capacity, then allocates the array:
// public interface
template <class Object>
FHvector<Object>::FHvector(int initSize)
{
setSize(initSize);
setCapacity(mSize + m_SPARE_CAPACITY);
mObjects = new Object[mCapacity];
}
This, then, always guarantees an object is constructed that makes sense, no matter what the client passes.
The copy constructor is trivial because it is based on the assignment operator. Therefore, I'll show you the assignment operator immediately following it:
template <class Object>
FHvector<Object>::FHvector(const FHvector& rhs)
{
mObjects = NULL; // needed for following
operator=(rhs);
}
// assignment operator
template <class Object>
const FHvector<Object>& FHvector<Object>::operator= ( const FHvector& rhs )
{
int k;
if (this == &rhs)
return *this;
delete[] mObjects;
setSize(rhs.mSize);
setCapacity(rhs.mCapacity);
mObjects = new Object[mCapacity];
for (k = 0; k < mSize; k++)
mObjects[k] = rhs.mObjects[k];
return *this;
}
Finally, we will do the trivial destructor in-line, that is, in the prototype, so no need to qualify it using the scoping operator:
~FHvector () { delete[] mObjects; }
2A.2.4 resize() and reserve()
Increasing the size really doesn't do much if the new size is still less than the capacity. It simply states that there are more "active" elements in the vector. These new elements are already there, so they will contain default Objects. If we are diminishing size, it's even easier to understand. We are basically throwing away some of the elements on the tail of the array. Either way, if the new size is less than the capacity, it's easy. If the new size is greater than the capacity, then we have to reallocate memory.
Which brings us to reserve(), the true allocation workhorse of the container. This will allocate more memory, copy the old array into the new one, then free-up the old memory. If the new requested capacity is less than the existing capacity, we do nothing. We never decrease capacity.
Here are resize() and reserve():
template <class Object>
void FHvector<Object>::resize( int newSize )
{
if (newSize <= mCapacity)
{
setSize(newSize);
return;
}
reserve(2*newSize + 1);
setSize(newSize);
}
template <class Object>
void FHvector<Object>::reserve( int newCapacity )
{
Object *oldObjects;
int k;
if (newCapacity < mSize)
return;
setCapacity(newCapacity);
oldObjects = mObjects;
mObjects = new Object[mCapacity];
for (k = 0; k < mSize; k++)
mObjects[k] = oldObjects[k];
delete[] oldObjects;
}
Notice that when a new size is requested, we allocate double (roughly) that size if we need to do reallocation. There is a theoretical reason for this that we will discuss when we get to hashing.
Let's pause and look at the last three lines of reserve(). Can you see anything interesting? We are copying over a bunch of objects, then deleting the old objects. This will cause "big bad" problems if the class to which those objects belong has deep memory and has not correctly overloaded the assignment operator. That class's destructor will ostensibly delete that deep memory, which means this assignment had better be a deep copy! We cover copy constructors, assignment operators and deep copies in CS 2B, so if this is not clear to you, please review those concepts. The point is, FHvector is not responsible for the Object's memory management. That needs to be handled by the client, and if it isn't, there will be crashing and burning, and there is nothing we can do about inside FHvector.
This section covered the careful work of allocating and re-allocating memory for the FHvector container. The remaining methods are the fun and easy ones, and we'll cover those in the next section.